
1日目に続き2日目は早速Pandasの操作編です。Pandasはデータ解析を支援する機能を提供するライブラリでデータの読み書き、クロス表の作成、基礎統計料の確認など、いわゆる一般的な集計・分析の操作が独自関数により簡略化されているものです。
レガシーな構文をつかって頑張って書くものありですが、Pandasを操作できたほうが何かと便利なので頑張って覚えましょう。
前提
kaggleのtitanicのデータを用います。そのままでも使えますが、CSVファイルになっているので使いやすいように前処理を済ませておいてください。
⇒ Titanic: Machine Learning from Disaster
本セクションでお伝えする処理に、前処理は含みません!!
会社でもメンバーに伝えていたことですが、Pythonで行うよりも前処理に適した言語が沢山あります。
※SQL、VBA、CSVエディタ、EXCEL、SPSSModeler、Alteryx等
PythonにはPythonの長所がありますし、前処理には前処理に適した言語やツールを使うべきだと思っています。また、様々な言語やインフラに触れてほしいと思っています。
例えば、SQLですと、ローカルにポスグレを立ててもいいですし、AWSの無料枠でS3とAthenaを使っても良いかと思います。1つの言語に特化しすぎると市場での(自分の)売り方が狭まってしまうので。
データフレームに読みこむ
何はともあれpandasとtabulateをインポートしておきます。
tabulateはコマンドプロンプトやターミナル上でもテーブルをキレイに装飾してくれるライブラリです。
Jupyter NoteBookでキレイに描画すればいいじゃん・・・と言われそうですが
軽量なターミナルでサクッとテーブル表示したいときおすすめです。
※決して私が10年前のPCたちで分析を行っているからではありません。
何はともあれデータフレームに読みこんでおきます。オプションの引数については1日目のレクチャーを参考にしてください。
|
1 2 3 4 5 |
#! /usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd</pre> df = pd.read_csv('/titanic.txt' ,encoding='utf-8', sep='\t') |
チートシート
Rには「これだけ覚えておけばとりあえず大丈夫!!」というチートシートが割とあるのですがPythonの特定のライブラリ、今回で言うとPandas専門のチートシートがないいか調べてみました・・・・・なんと片桐さんという方が日本語版のパワポをgit上に公開しておりました。よろしければ参考にしてください。感謝しながら使いましょう!!
https://github.com/Gedevan-Aleksizde/pandas-cheat-sheet-ja
Pandas操作編
それでは早速はじめます。
データ型の確認
pandasデータフレームの型を一括で確認できます。
|
1 |
df.dtypes |
またPythonの型には以下のようなものがあります。
・str: 文字列
・int: 整数
・float: 浮動小数点
・bool: True or False
・datetime: 日付
・その他:list,tuple,dictionary
カラム名・値の確認
head関数はテーブル内のカラム名・値の確認を行う為に用います。デフォルトは先頭5行が出力されますが()内の引数として整数を渡してあげれば指定の行数が出力されます。
|
1 2 |
df.head() df.head(100) |
要約統計量を調べる
describe関数を用いることで、標準偏差や算術平均を求めることができます。
手っ取り早く確認するときは、小数点がやたらと表示されてしまうのでround関数をネストさせてあげることが多いです。
※通常案件では小数点の最後尾まで全部値を残して置きましょう。
|
1 |
print(round(df.describe(), 2)) |
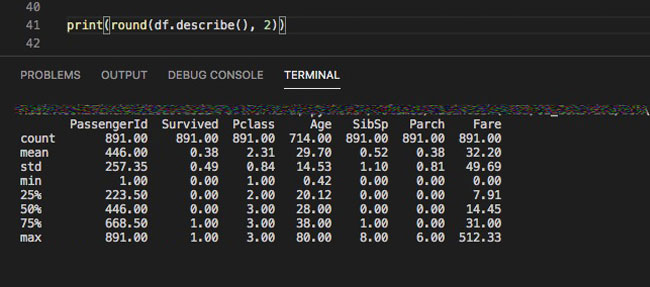
そのまんまですが以下のようなものが出力されます。
- count: 要素の個数※SQLのCount
- mean: 算術平均
- std: 標準偏差
- min: 最小値
- 25%: 四分位数(しぶんいすう)の25パーセンタイル(第1四分位数)です
- 50%: 四分位数(しぶんいすう)の50パーセンタイル(第2四分位数)です※中央値medianと一緒です。
- 75%: 四分位数(しぶんいすう)の75パーセンタイル(第3四分位数)です
- max: 最大値
top: 最頻値(最も出現する値)
freq: 最頻値の出現回数
なども知りたい場合は、数値。文字列なく関係なく出力できるオプション、include=’all’を使ってあげれば良い。
|
1 |
print(round(df.describe(include='all'), 2)) |
テーブルの基礎情報を調べる
受領したデータの型を調べたり、中身の値の確認は、忘れずに最初にやる習慣をつけましょう。
info関数ではデータの型や、欠損の有無などを調べられます。
※テーブルの下までプログラムが舐めていきますので、数千〜数億レコードの縦持ちデータには向きません。
|
1 |
print(df.info()) |
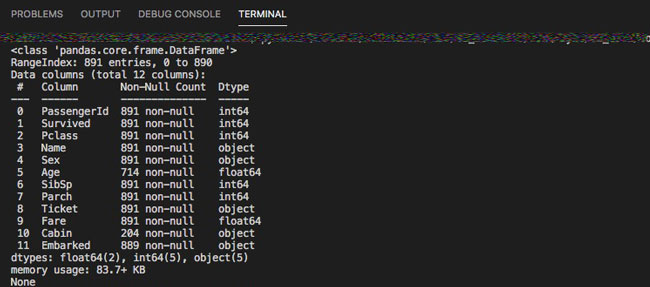
データ型を調べる
info関数でデータの型も調べられましたが、単純に型だけ知りたい場合はdtypes関数で調べられます。
|
1 |
print(df.dtypes) |
![[python]dtypes](https://310ch.net/wp-content/uploads/python-dtypes.jpg)


