XPath とはXML Path Languageの略で、その名のとおりXML形式の文書を解釈して切り取ることができる言語です。アナリティクスの業務ではスクレイピング時などに使用する事が特に多いかと思います。
今日はよく使う記法についてのまとめです。
対象要素の調べ方
最初から書かなくてもChromeの開発者ツールでXPathの記法を調べる事ができます。
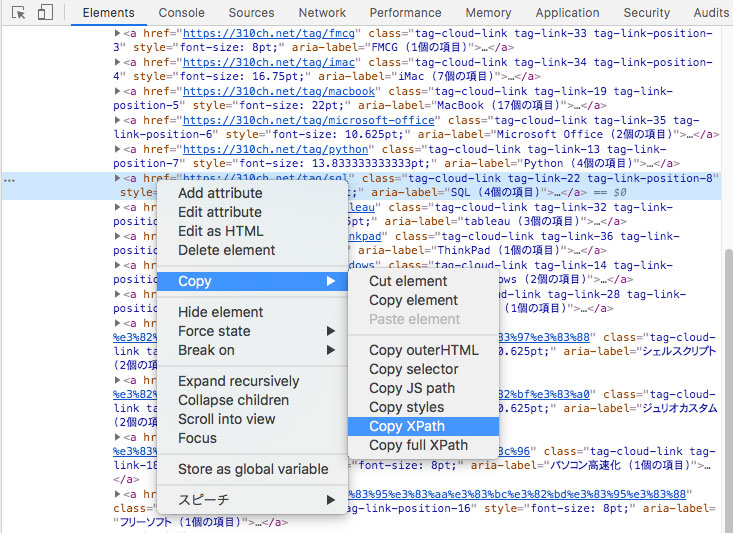
操作方法は開発者ツーで必要なHTML要素を右クリックしElementタブのHTMLタグ部分で[Copy]⇒[Copy XPath]をクリックすれば良い。
するとクリップボードにXPathの記法がコピーされる。↓↓
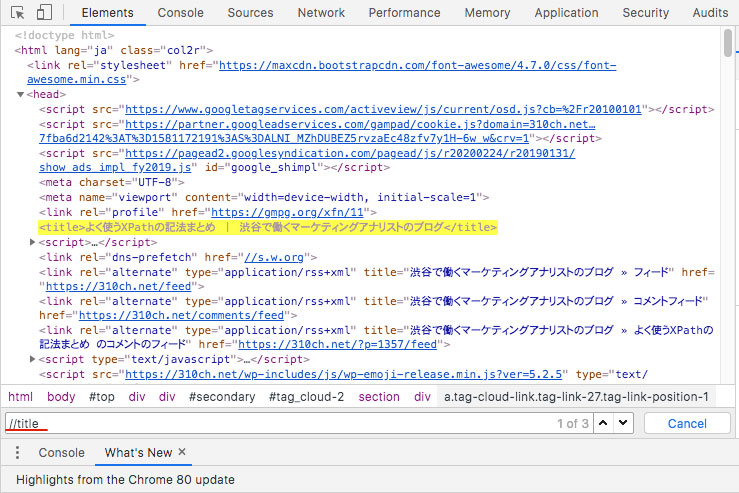
その記法が正しく機能しているか?調べるにはControl + Fで検索窓を出して、そこにXPathを入力すると、対象の要素がマーキングされる(されなかったら記述が間違っています)↓↓
ただし、あくまで参考で実務ではこのまま使うことはほぼないので、自分で記述する方が望ましい(VBAの自動マクロもそのまま使わんでしょ?)
・・・ということで基本的な構文をまとめました。
構文 – クラス要素を取得する
HTMLのClassを取得します。
|
1 |
//div[@class='HtmlClassName'] |
先頭に//と書けばルートから書かなくても判別してくれます。
構文 – 最初/最後の要素だけ
CSSの:first-child疑似クラスのような特定要素の最初だけ、または最後だけという指定です。first()関数もしくはlast()関数を使います。
|
1 2 |
//div[first()] //div[last()] |
構文 – n番目の要素
first()関数を使うより最初だけならこっちが使いやすいです。
|
1 |
//div[1] |
構文 – n番目の要素とn番目の要素の間
n番目の要素とn番目の要素を追加したい場合、preceding-sibling要素を使用します。